Connecting Ops in Jobs#
Our jobs wouldn't be very interesting if they were limited to single ops. Jobs connect ops into arbitrary DAGs of computation.
Why split up code into ops instead of splitting it up into regular Python functions? There are a few reasons:
- Dagster can execute sets of ops without executing the entire job. This means that, if we hit a failure in our job, we can re-run just the steps that didn't complete successfully, which often allows us to avoid re-executing expensive steps.
- When two ops don't depend on each other, Dagster can execute them simultaneously.
- Dagster can materialize the output of an op to persistent storage. IO managers let us separate business logic from IO, which lets us write code that's more testable and portable across environments.
Dagster jobs model a dataflow graph. In data pipelines, the reason that a later step comes after an earlier step is almost always that it uses data produced by the earlier step. Dagster models these dataflow dependencies with inputs and outputs.
Let's Get Serial#
We'll expand the job we worked with in the first section of the tutorial into two ops that:
- Get the sizes of all the files in our directory.
- Report the sum of the file sizes. In a more realistic setting, we'd send an email or Slack message. For simplicity, we just emit a log message.
This will allow us to re-run the code that reports the summed size without re-running the code that crawls the filesystem. If we spot a bug in our reporting code, or if we decide we want to change how we report it, we won't need to re-crawl the filesystem.
import os from dagster import get_dagster_logger, job, op @op def get_file_sizes(): files = [f for f in os.listdir(".") if os.path.isfile(f)] return {f: os.path.getsize(f) for f in files} @op def report_total_size(file_sizes): total_size = sum(file_sizes.values()) # In real life, we'd send an email or Slack message instead of just logging: get_dagster_logger().info(f"Total size: {total_size}") @job def serial(): report_total_size(get_file_sizes())
You'll see that we've modified our existing get_file_sizes op to return an output, in this case a dictionary that maps file names to their sizes.
We've defined our new op, report_total_size, to take an input, file_sizes.
We can use inputs and outputs to connect ops to each other. Here we tell Dagster that:
get_file_sizesdoesn't depend on the output of any other op.report_total_sizedepends on the output ofget_file_sizes.
Let's visualize this job in Dagit:
dagit -f serial_job.py
Navigate to http://127.0.0.1:3000:


A More Complex DAG#
Ops don't need to be wired together serially. The output of one op can be consumed by any number of other ops, and the outputs of several different ops can be consumed by a single op.
import os from dagster import get_dagster_logger, job, op @op def get_file_sizes(): files = [f for f in os.listdir(".") if os.path.isfile(f)] return {f: os.path.getsize(f) for f in files} @op def get_total_size(file_sizes): return sum(file_sizes.values()) @op def get_largest_size(file_sizes): return max(file_sizes.values()) @op def report_file_stats(total_size, largest_size): # In real life, we'd send an email or Slack message instead of just logging: get_dagster_logger().info(f"Total size: {total_size}, largest size: {largest_size}") @job def diamond(): file_sizes = get_file_sizes() report_file_stats( total_size=get_total_size(file_sizes), largest_size=get_largest_size(file_sizes), )
First, we introduce the intermediate variable file_sizes into our job definition to represent the output of the get_file_sizes op. Then we make both get_total_size and get_largest_size consume this output. Their outputs are in turn both consumed by report_file_stats.
Let's visualize this job in Dagit:
dagit -f complex_job.py
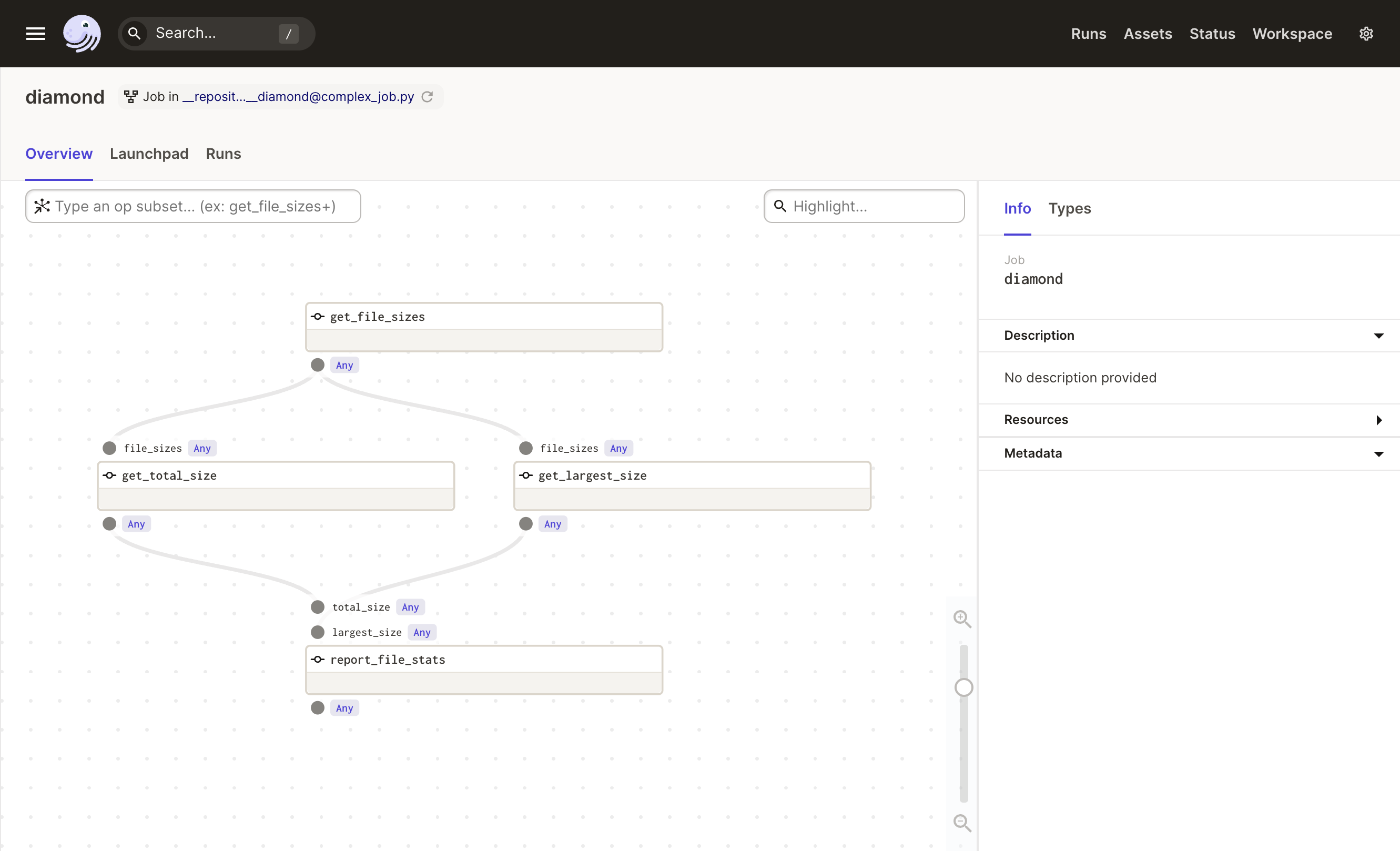
When you execute this example from Dagit, you'll see that get_file_sizes executes first, followed by get_total_size and get_largest_size executing in parallel, since they don't depend on each other's outputs. Finally, report_file_stats executes last, only after get_total_size and get_largest_size have both executed (because report_file_stats depends on both of their outputs).